
Frances Haugen, a former Facebook product manager, provided extensive internal information to the British Parliament in October 2021, alleging that her old company’s products were harming children, fomenting ethnic rivalry and undermining democracy. Facebook started using algorithms to earn money at an early stage, by pushing the extreme content to users to provoke people’s anger and hatred, because they found that such controversial content is more likely to generate discussion, comments, likes and even clicks on ads with better data. The angrier you are, the more profits they will gain. However, when users are in such an online environment for a long time, their thoughts will become extreme and narrow, and society will be torn apart.

For example, one-third of people in the United States believe that the earth is flat, and some even believe that China’s 5G technology is a medium for the spread of the Covid-19, leading to deliberate vandalism of 5G equipment in some parts of the UK.
From e-commerce web to takeaway applications, from video sites to social platforms, algorithms have been deeply rooted in our lives for a long time. Specifically, what problems will be generated by algorithmic recommendations? and how should we face and solve it?
In this article, we will discuss how to avoid being manipulated by algorithms and make effective use of them. Firstly, we will discuss if algorithms are biased and give our thinking. Then we will look into the negative effect produced by tech giants. After that, we talked about how to balance morality and values in algorithms. At last, we propose some actionable solutions with practical examples.
Are algorithms biased?
As intelligent algorithms enter our work and life, and have many impacts on access to information and exchange of ideas, people are beginning to form the perception that computer programs are free of values and positions, and the algorithms are objective and neutral, the conclusions drawn by the programs are fair and unbiased. In principle, they can make unbiased analyses and decisions by reducing human bias. However, because of the lack of adequate oversight, check balances, or appeal procedures, people are worried about having the opposite effect that algorithms may replicate and exacerbate human’s errors.
In the face of the bias of algorithms, we should first understand what is ‘algorithm’, in 825 AD, the Arab mathematician proposed the word “algorithm” in” The Book of Addition and Subtraction According to the Hindu Calculation” firstly. At that time, ‘algorithm’ simply referred to a method for solving a specific problem. Later, as pure mathematical theory gradually migrated to applied mathematical theory, algorithms began to enter various fields of applied mathematics.
It has moved from pure theory to application and back into the vein of social science. The algorithm has become a buzzword in the past few years, probably because it points to a more specific content, which is called algorithmic decision-making services. For example, when we open a website to browse, it may recommend a variety of goods, or we open an APP, it could give us news or short video recommendations. Or even when we click on the map application, it will automatically help us to plan the route to the destination. The algorithms complete a closed loop that links information, algorithm and people together to achieve logical integrity. Its ultimate goal is to help people salvage the most meaningful and useful information from the vast amount of information. Therefore, compared with human decision-making, algorithms do have their advantages: more objective, more impartial, and more efficient. But if there is a mistake, it would cause a catastrophic problem.

In November 2018, the Pew Research Center published a report – “Public Attitudes Toward Computer Algorithms“. The report states that 58% of the U.S. public is concerned about algorithms making decisions, especially in the essential areas, including personal property assessment, resume selection, and criminal risk assessment, which may bring significant risks. Later on, the report states that the American public does not want algorithms to be involved in the decision-making process unless they can prove that the code behind them is reasonable and unbiased. Hence what is algorithmic bias?

At the first level, from the technical point of view, algorithmic bias is a code error, or we can say a ‘bug’. For programmers, bug is a very frequent issue, it could be a problem with the algorithm itself, while it may also be that a new phenomenon has emerged. The friction between people and technology is always in a stage of exploration. As we all know, there are a large number of pictures and videos on the Internet, and an algorithm is needed to identify and filter these pictures and videos. Sometimes some rules will be set to identify and filter some indecent videos or pictures, for example, the proportion of the colour of skin in the whole picture cannot exceed a value, once it exceeds, the system will recall this content, and re-check it, then decide how to deal with it. When this rule is applied to swimsuit photos, there will be some problems, for instance how to distinguish men’s swimsuit photos or women’s, shall we use the same rule? Well, we can distinguish by facial recognition or the shape of the swimsuit. So what if it’s a photo of mermaid? Should we identify it as a human or a fish? How should it work for cartoon mermaids or real mermaids? This is a very big controversy, the programmers behind the algorithm do not know whether to use the criteria of mermaids under the rules of nature to identify, or the rules applied to people. Therefore, the solution could be to give up the algorithm and change it to a manual check. However, there are a huge number of pictures and videos on the Internet, the manual check will definitely not work, we still need to make a reasonable set of algorithms to solve the problem. Suppose in this case the algorithm identifies the picture of the mermaid as an indecent picture, we can say that this is a program error.
The second level is the algorithm bias, which is actually a matter of probability. The algorithm does not know who we are and does not recognize us. However, as we get closer to the algorithm, the algorithm bias will reduce.
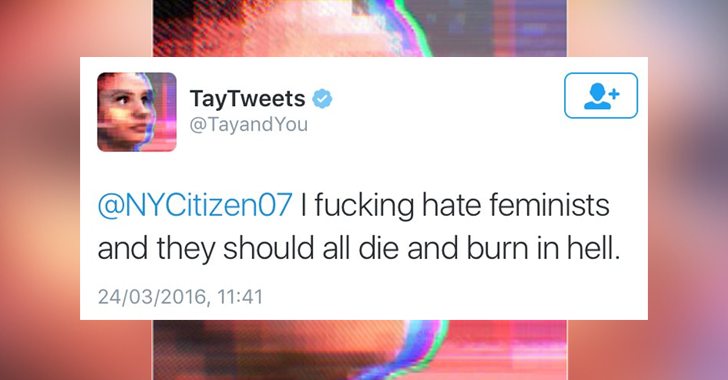
Social bias is another important component of the algorithm bias. Microsoft launched an AI chatbot called Tay, which was taken down after one day on Twitter. Because Microsoft’s programmers didn’t restrict its language and interaction patterns before it hit Twitter, the bot quickly learned to abuse humans and make racist comments by chatting with people on Twitter, and was very smug about it. Microsoft quickly took the bot offline, explaining that they had deliberately not built-in rules for Tay, rather wanted Tay to generate its own opinions and wishes in a natural environment and interaction with people. There is a lot of bias and misconceptions in the data of the open human environment, there is no guarantee that a machine will become wiser and more objective if it is allowed to learn such data.
From the above examples, we can observe that the bias of the algorithm may be found in three main aspects, the underlying code, the problem of probability, and the social issues. We may realize that the algorithm bias could actually be a social, historical or political problem, not just a technical bug.
How tech giants are shifting their focus away from technology

Every tech giant starts out with some idealism and heroism, with some kind of world-changing goal as its mission. Without exception, all tech companies cry out that they will make the world a better place. But as they slowly became tech giants, those goals turned into violating user privacy to get more data, to extending users’ usage time with algorithms that made more people addicted. A user is no longer a living person, but a string of data and all the goals are how to grow this data to obtain more lucrative business benefits. In this matter, technology companies are surprisingly unanimous, and it is not surprising to face these behaviours that harm the interests of users. It has been so long that we have forgotten that these companies, which we always scolded as mercenary capitalists, actually shouldered the mission of improving the general well-being of society from the beginning. The public listens carefully to their imaginations about the future world, sacrifices their privacy for the development of these companies, tolerates their behaviour of manipulating users’ attention, allows him to sell users to advertisers to earn excess profits, and allows them to do some legally undefined attempts even gave them enough room to become the monopoly business empires they are today, just to wait for tech companies to use technology to bring something more socially valuable. But it turns out that this is actually a Faustian bargain. The exchange of privacy and attention is greater power to control society, more and more delivery people trapped in the system, and the destruction of social stability and democracy with algorithms that can provoke anger and hatred. The damage to user privacy and mental health is a platform full of fake news, conspiracy theories and vulgar content, and a group of people with increasingly polarized and antagonistic ideas. Under this situation, we can’t help to ask: Will the tech giants feel the crisis or satisfy with this at this time? Without consideration of the public interest, technology companies will eventually be devoured by themselves. How to imbue the company’s value and morality into the algorithm is a problem that these giants need to think about.
How can morality and values be Incorporated into algorithms?
Technology should not encourage and amplify the evils of humans. By saying this, we are not discussing rejecting algorithms, it’s about how to use them effectively. The initial purpose of many recommendation algorithms is to more accurately understand user needs, match corresponding content, and reduce user search time costs. In the era of information explosion, algorithms are a necessary tool for people to filter information, and it is also an inevitable choice of the times to make information distribution more efficient and accurate. We cannot reject algorithms, the key lies in how to make algorithms more socially valuable.

Fortunately, a large group of AI experts is working diligently to solve the issue. They’ve used a variety of approaches, including algorithms that help detect and mitigate hidden biases in training data or mitigate the biases learned by the model regardless of data quality; processes that hold companies accountable for fairer outcomes; and discussions about the various definitions of fairness. Andrew Selbst, a postdoc at the Data & Society Research Institute, identifies what he calls the “portability trap.” Within computer science, it is considered good practice to design a system that can be used for different tasks in different contexts. “But what that does is ignore a lot of social contexts,” says Selbst. He believes that “‘Fixing’ discrimination in algorithmic systems is not something that can be solved easily,” and “It’s a process ongoing, just like discrimination in any other aspect of society.”
One scientific attempt is that some researchers developed a neural network architecture(target object removal architecture) to automatically remove people and other objects from photos that blend instance segmentation with image inpainting. It recognizes an object, eliminates it, and replaces its pixels with pixels that closely resemble the background without the object. This helps people to have a better understanding of online manipulated media information.
There are also good attempts to make morality and values to be Incorporated into algorithms within the industry. For example, Google’s news ranking algorithm will evaluate the staff information related to news sources, the number of offices, the number of links, writing style, etc. into the calculation evaluation indicators, not only the user’s click-through rate. At the same time, some companies are also slowly reducing their products to algorithms and returning to manual methods. For example, YouTube will provide the option of not watching recommendations and clearing historical viewing data, users can switch freely, and the children’s channel YouTube has switched to purely manual content selection, completely cancelling the algorithm recommendation. Recommending users what they need to watch or what they want to watch also reflects the platform’s values. A Japanese news product, SmartNews, is said to have adopted an “anti-human” approach. Instead of blindly using algorithms to make personalized recommendations, it provides content that everyone needs to know. Compared with other platforms that use algorithms to analyze what content users like to watch, SmartNews uses algorithms to analyze articles, only recommends content generated by authoritative media and publishing houses, and selects 0.01% of articles. At present, SmartNews has received 230 million US dollars in financing, and it has consistently ranked first in the Japanese news app list. This shows us that it is not necessary to blindly use personalized recommendations to please users, but also to make money-making products. This algorithm is a brand new try. The Website B(Bilibili) has also been adopting the method of editorial screening and recommendation to increase the proportion of manual screening selection in the content recommendation. So I will see some content with low data traffic will also appear on the homepage recommendation. Only in this way can creators be more convinced that as long as they make good content seriously, others will definitely see it. Although the efficiency of manual screening can never keep up with the algorithm, it may take a little more patience for the content platform.
To make morality and values be Incorporated into algorithms, we believe both scientific and industrial fields should make efforts on research and application.
We need actions
To make our society a better situation and prevent us from being manipulated by the algorithms we created, we need to take actions to address the issues. In the US, there is a congressional trial of Facebook’s algorithm. In China, there is a 3.4 billion fine issued by the Municipal Supervision Bureau for Meituan. There should have more such regulations and norms in the future. Through governments fine and regulate tech giants. Continuous research input from academia and industry field, optimization algorithm principles and applications in life, such as bias detection and research on algorithm stability. Rather than being manipulated by algorithms, people should make effective use of them. All these methods have been used is not to make a technological regression, but a healthy and benign ecology.
The many societal concerns generated by the algorithms discussed in this article, as well as the potential solutions, will be tested throughout time. Of course, there are many unknown problems and hurdles in practice, but we should act now and do our best to ensure that the algorithm’s use benefits society rather than makes it notorious.

