In the years following the second world war, the process of decolonisation started: Countries previously exploited could, for the most part, finally declare independence from their colonisers. The mid-20th century marked a turning point in history, as nations sought autonomy and liberation from the shackles of imperial rule. Fast forward to the 21st century, and we find ourselves in a new form of colonialism: Data colonialism. Large corporations are using this massive amount of data for their own gain. In this article, we aim to argue the problems that arise with data colonialism and how it should be regulated by the government.
Data colonialism in its current form
Data colonialism can have several definitions. Here we define data colonialism as the process by which governments, non-governmental organizations and corporations claim ownership of, or privatize the data that is produced by their users and citizens in order to exploit this data for personal gain. This colonialism has become very evident in some cases or countries like China for example. In China, the government can track the movement of specific individuals using the surveillance infrastructure they have created using the data of their citizens. While it can be argued that this data can be used for good, like for tracking potential criminals, the downside of this is that this data can also be used to marginalize certain groups of individuals. Another example of this is the use of the Top400 list in Amsterdam. This list consists of the top potential criminals in the city. These potential suspects may have never been involved in crime before but because their older brother or friend has done a criminal act, they can end up on the list and face extra stops and searches by the police. It has been found that suspects with an ethnical background have a higher chance of ending up on this list.
But it’s not only the governmental bodies that use this data in this manner, companies like Meta and Google also have a considerable amount of data within their possession. This data is collected from the accounts that are created on these platforms. Based on a user’s likes or other preferences, these platforms can create a network of information based on every individual on the website. This data can then, for example, be sold to other companies and institutions. It can also be used for personalised ads and recommendations.
On the other hand, it has been demonstrated that using certain sensitive data in AI algorithms for practices such as recruitment and loan eligibility, could help to reduce discrimination in the automated decision making. Most often, the algorithms contain a black-box mechanism which makes it hard to really understand a certain outcome. To better assess if an AI system is biased, the engineers need to know some sensitive data about the input. If the system is a job recruiter, then to assess if it is biased, its creators need to know the sensitive data of the job applicants and if they were recruited or not in order to accurately compare the outcome. Companies realised that without appropriate details about their data and input, they are less able to engage in adequate bias testing.
It is clear that new rules need to be instantiated because data will be more and more used to make AI systems more and more accurate. These rules will prevent the misuse of sensitive data from companies and the government. It could define appropriate safeguards for the population, GDPR exceptions to help assess discrimination in AI systems, and Data Governance which will protect the way data is collected and used. But first, let’s have a look at what is already in place today.
Current Regulation and consensus
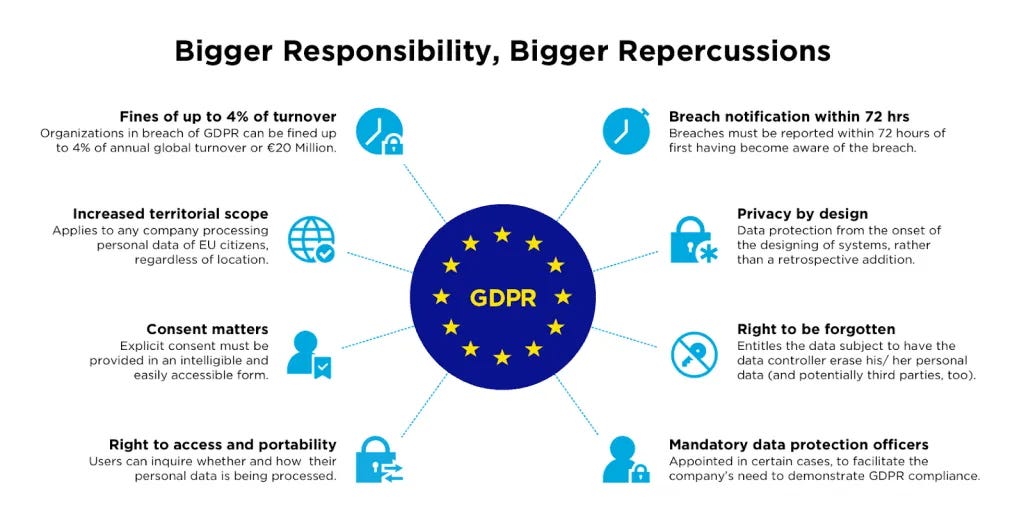
These technological advancements are occurring at a very rapid rate so the regulation on this matter is trailing behind. The European Union does have a General Data Protection Regulation (GDPR) act. This act grants individuals greater control over their personal data, including the right to access, rectify, and erase their data. It also states how organizations must obtain clear and affirmative consent from individuals before collecting and processing their personal data. Other measures include the use of limited access to the data companies have and users being allowed to request their data to be sent to themselves. There are also methods that enable individuals and organisations to protect their sensitive data by themselves such as encrypting one’s data, the use of a VPN, or using a password manager.
While these measures are already shown to be effective, like Meta being fined 1.2 billion euros for violating the rules in 2023, it also has some potential flaws. The measure of needing consent from individuals before collecting and processing their personal data is often done through terms and conditions or cookies that are being shown to the users before they can use these platforms. A study by Business Insider found that 91% of Americans do not use the terms and services. A different study also shows how 40% of Americans blindly accept these cookies without even looking at them. The procedure of asking for consent is not effective enough and needs to be adjusted.
Concerning the detection of biased algorithms and the use of sensitive data, the data minimisation standards are really strict and limit the extent to which an algorithm can be tested. It has been the case that organisations carried out data minimisation to such an extreme that they were not able to test whether their algorithms induced discrimination, nor test whether its predictions were accurate at all. To counter those limitations, there are already a couple of methods that can be used in order to achieve such an assessment. The first of which is directly collecting some sensitive data with the consent of the individuals. However, the GDPR allows such actions only in a few fields of work. The second method which is more accessible is to generate intentional proxies, the operators can intentionally and efficiently infer demographic data from the less sensitive information they have on file, which would help assess an algorithm’s bias and accuracy.
Potential Solutions
There are a few solutions that could be implemented in order to help with the issues stated above.
Firstly, we think the GDPR is a good step in regulating data colonisation, but it is not only an issue for the European Union. We think a good step forward is to enforce these rules also on a global level in the United Nations. This way other countries and corporations can also be held accountable for breaching data-specific rules.
Secondly, it is often overlooked by companies but Data Governance is one of the success factors for Big Data Algorithmic Systems (BDAS). It is defined by the organisations stating and applying the rules for directing proper functioning and accountability of the entire life-cycle of data within and across organisations. If companies would spend more time ensuring a transparent, safe, and fair data life-cycle, there would be fewer concerns by the population about what happens to their data.
Thirdly, concerning the use of sensitive data, a few articles ask the GDPR to make an exception to the ban on using sensitive data for algorithms testing. This exception would allow for more accurate tests and better assessment of discrimination in systems’ outcomes. But as it touches sensitive data, new safeguards would have to be implemented so as to not violate privacy. Such safeguards imply the anonymisation of the data, a strictly necessary need for preventing discrimination and it should only apply to providers of a high-risk discriminating system.
Lastly, we think it is important for the users to be informed about how their data is going to be used in a more clearly. We think the terms and services should be either depicted in small, easy to digest, bullet points that summarize the terms and services. This way, users can make a more informed decision on how they want their data to be used.
What now?
It seems that the way to go is to embrace this movement which doesn’t seem to slow down. The government will have to implement new appropriate safeguards and rules which prevent the misuse of private data. If the corporations perform correct Data Governance and appropriate bias testing, those issues should mellow down. On the population side, there will probably be more options to protect their sensitive data on top of what already exists.
New regulation is needed and needs to be enforced!


