
“If you are doing something that you don’t want other people to know, maybe you shouldn’t be doing it in the first place.”
Said by Google ex-CEO Eric Schmidt. In his opinion, Google was merely a conduit and was not responsible for the invasion of people’s privacy. His attitude shows that he doesn’t seem to care about personal privacy at all. But is that really the case? When a reporter from CNET tried to rundown things that a short Google search had revealed about Schmidt, such as his net worth, his hometown, and his trip, Eric Schmidt was so angry that he banned CNET from google for 15 years. And that wasn’t the only case, Mark Zuckerberg brought 4 houses surrounding his own home to ensure privacy although he thought privacy is not a “social norm” anymore.
Those people who held the idea that “I don’t care about the mass surveillance and invasion of data privacy, I have nothing to hide.” Do they really don’t care? It’s just easier to claim in words that they don’t value their privacy, but their actions negate the authenticity of that belief. They set passwords to their email and social media accounts, they put locks on their bedroom and bathroom doors. They do all actions to prevent others from entering what they think is their private realm.
Your data is your fingerprint
Our personal data is a valuable economic asset. With every device that we log in to, we compromise a part of our identity. Facebook, Snapchat, Google, and every other big tech data company that swear to keep our privacy, not only collects and stores them but also trades them with international companies. With the GPS and data locators, knowingly, unknowingly, we leave a trail of digital footprint wherever we go. These traces get picked up to create a digital blueprint of an individual, which is further used to control and manipulate us, in terms of fake news, micro-targeting, and bio-hacking.
The idea of ‘anonymity’ in the online world does not serve its purpose anymore. In recent years, it has been seen that re-identification of individual ‘anonymous’ data from various metadata is quite easily possible.
A study at the University of Melbourne found that confidential patient data can be re-identified, without decryption, through a process of linking the unencrypted parts of the record with known information about the individual such as medical procedures and year of birth. The Massachusetts Group Insurance Commission, in the hope, to help researchers, released the “anonymized” data of state employees that showed every single hospital visit, which later, proved to be a breach of privacy.

How would you feel if someone just shows up at your door and says that they have your entire browsing history, every day, every place, every hour, every minute? Would you feel like you were hacked? But, it’s much more simple. Eckert, a journalist along with data scientist, Andreas Dewes, found that getting hold of a user’s browsing history was much easier than thought. They could literally buy the data for free from data brokers. Millions of data on the web about an individual get sold to software and analytics companies for testing and validating their software, for surveys and analysis. If not efficiently looked into the algorithms of search engines and different websites, companies are in no way capable of keeping their promises as per their privacy policies. A similar strategy was used to deanonymize a set of ratings published by Netflix to help computer scientists improve recommendation algorithm: by comparing “anonymous” ratings of films with public profiles on IMDB, researchers were able to unmask Netflix users – including a woman, a closeted lesbian, who went on to sue Netflix for the privacy violation.
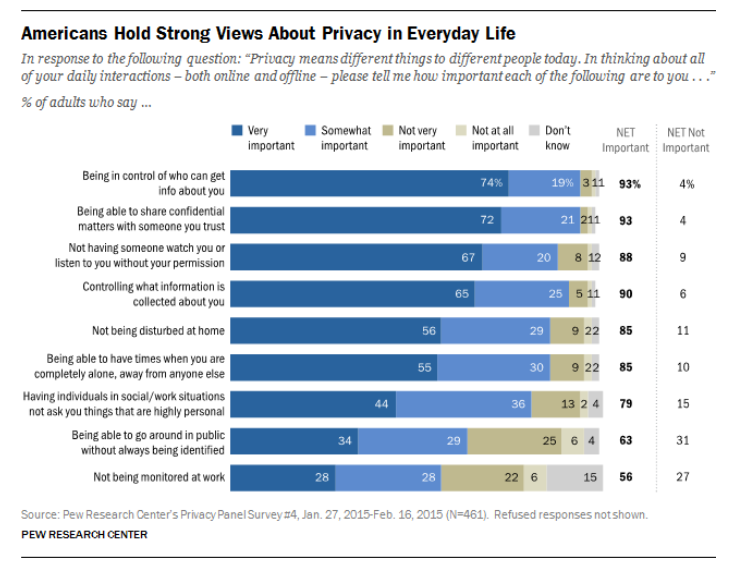
Starting from a single picture to updating the status to tagging a person, every little detail that we post on the web, on Facebook, Twitter, however “private” we think they are, can be easily used against us. Working with publicly available metadata from Twitter, a machine learning algorithm was able to identify users with 96.7 percent accuracy. In the testimony to a Department of Homeland Security privacy committee, Latanya Sweeney told that data which may look anonymous may not be necessarily anonymous. Sweeney showed that 87% of the population of the United States could be uniquely identified by just their date of birth, gender, and five-digit ZIP codes. In a survey conducted by the Pew Research Centre, most Americans hold strong views about the privacy of their data in everyday life and many have little confidence that their data will remain private and secure.
Even those fitness trackers that you wear and the fitness apps profiles that one creates to track their progress, location, and distance get recorded. This data can be used against the individual and can prove dangerous by exposing a person’s home route, military bases, secret locations, and soldier’s or officer’s identity.
Data gets collected unknowingly and without individual consent through large-scale surveillance and facial recognition software. Your daily activity on the internet is actually creating a digital fingerprint.
Consider the following example:
Imagine you are using an online bank to apply for a student loan. In order to give you credit, they ask you to fill in an online form and some of your basic information such as your address, name, job, and age. Then they ask you to authorize your data on your phone and your transaction data for evaluating you. After that, Facial Recognition is needed to ensure you are you. Every step seems reasonable. You just give out your data, and you can earn something, such as a loan, a free subscription, or an account for some services.
After collecting these raw data, these data are being mined to label you.
Those tech companies pay lots of money to employ some of the smartest people and data scientists to mine your data. They divide your data into different groups, for example, different age groups, different regions. They create new features through your raw data, in almost every aspect about you, what’s your address, how much income and net assets you have, what’s your hobby, even your personality. For example, by analyzing history overdue data, they discovered that regularly calling someone and paying the money back on time are correlated. And if your call log data shows that you regularly call your parents and friends, you will be labeled as a responsible person, willing to return the loan.
They use advanced models to predict your actions.
With the development of AI technology, more and more advanced models are researched and published to take advantage of this data. For example, LSTM is used to handle time-series data. When using this kind of model is used, on the basis of historical data, even it can be predicted which button you will click next, even if you just give some basic information to apply for a loan. In fact, your private data already gets leaked. In a way, you are almost “naked” in the big company’s eyes. And those data will not disappear, they will store these data in their database, even share the data with other companies to seek their own benefit.
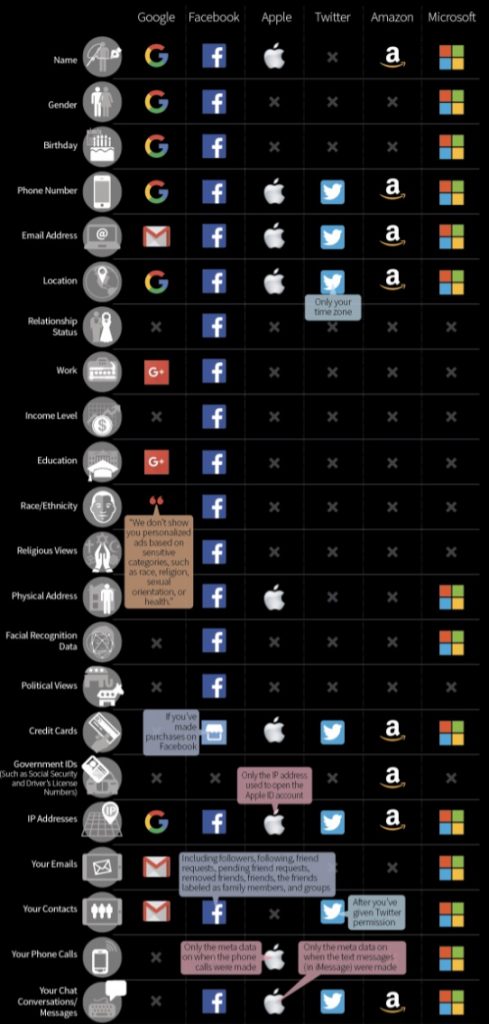
Google, Facebook, Twitter, Amazon, and other big tech companies, are all collecting more data than they have to. This picture shows what kind of data they are collecting.
Protecting Data is a matter of Urgency!
With the advancement of technology and new apps on the market, every invention is a matter of interest. How cool it sounds to be able to unlock your phone by just putting it in front of your face or just standing in front of biometric doors and making them open on their own.


Well, the facial recognition software makes it all possible. However cool it might sound, the potentials of facial recognition are far beyond just our phones. In many places, mass surveillance cameras are installed in public places equipped with this software. Every face in the crowd gets scanned and matched with an ‘on-file’ database to verify the individuals in real-time. These technologies get deployed on the basis of national security and an attempt to prevent crimes, secure transactions, greater accountability, improved economic productivity, commercial services, and better healthcare systems. Facial morphological features are often used to understand the mood, intention, and personality of individuals. Even though with all these benefits, there are glitches. There have been reports of facial recognition software failing to recognize African American faces due to the racially skewed data sets that the algorithms are trained on. In some cities, they are used to identify and publicly shame jaywalkers by displaying their names on electronic billboards. Politicians use it to keep a check on protestors and opponents, target political dissidents and restrict their access to services including trains and airplane travel. This violates civil and human rights. The protection of personal information is key to freedom of thought. What would happen to us if we knew that someone was watching our every move all the time? We would be afraid of incurring criticism for our non-mainstream speech, and this surveillance leads us to self-policing. Generally, the boundaries of freedom of expression are determined by different countries and social contexts. But when the boundaries are determined by the people who hold our data, we have no say in the matter. Different psychological studies state that when we are continuously under surveillance, it tends to change our behaviors and decisions. Nonetheless, several groups of people think that it’s perfectly safe ‘being watched’. But, being a ‘plutonium’ in disguise, a face in the crowd today may become a face on target someday.
The free access to large public databases, together with the progress of Deep Learning techniques, aid in manipulating facial images using Deepfake methods. Fake images and videos generated using facial information are a great public concern. These types of digital manipulations are useful in various sectors like the film industry, cosmetics and makeup, where consumers can try on different styles in a virtual environment. In the wrong hands, this software can be dangerous to the public. They can be used for bad purposes like the creation of celebrity pornographic videos, hoaxes, and financial frauds. They can be easily used to manipulate videos and create controversies, like the popular video of Mark Zuckerberg saying things that he never said.
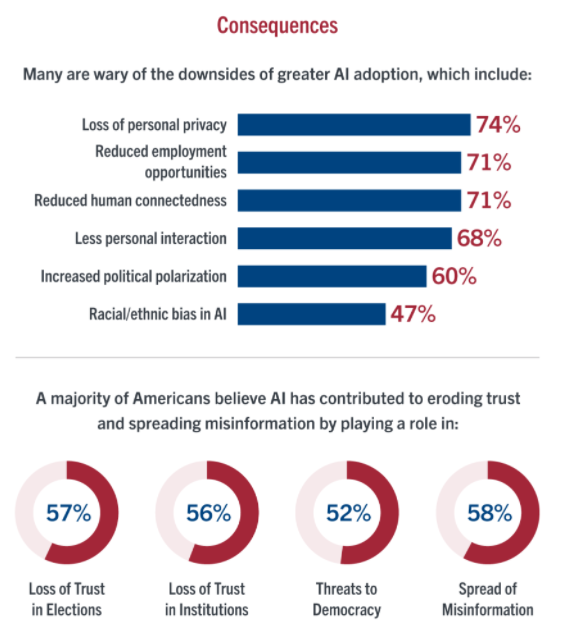
Personal data is being misused by big tech companies to polarize changes in media technology. In a poll conducted on behalf of Stevens Institute of Technology by Morning Consult between September 8-10,2021 among a sample of 2200 adults, majorities of adults believe AI has played a role in the loss of trust in elections (57%) and institutions (56%), as well as the spread of misinformation (58%), political polarization (53%), and threats to democracy (52%). The vast data online and in social media can be used to micro-target voters with hyper-personalized messages, biasing their decisions towards or against certain groups.
Every ‘Like’ button on Facebook can feed the algorithms into creating personalized content for the user. Your phone already knows what you want even before you say it loud. Every suggestion, recommendation, and notification is meant to satisfy you, trapping you in a box of your own thoughts. Too much use of these social media can sometimes lead to a loss of thinking out of the box attitude. Our lives are permanently saved as data that exists somewhere on the web, including our behavior and speech.
Take action from today
The development of big data is irreversible and inevitably leads to more and more serious problems of privacy leakage. What should be done to protect our data? Most people believe that such work should be done by the government. But, we need to start owning our data. It is not only the responsibility of the government but also, every individual. Everyone should enhance their awareness of privacy protection. Here are some steps we can take to help manage and protect our personal information.
- Individuals should disclose as little information as possible that is not necessary.
- When any new algorithm gets tested, there should be a legislative body to check on the datasets that are used to train the algorithm to avoid biasing in real-world scenarios.
- Programmers should be careful to code the algorithms using all possible solutions. The algorithms are created to be self-reliant. It learns from the real-world environment. There are users who mess up with these algorithms just for fun or to try out new stuff. In this process, the algorithms get trained on unnecessary data. There should be a check on these training sets.
- Awareness of privacy and personal information protection should be raised. “When downloading and installing mobile applications, read the user agreement carefully to understand what privacy rights you have. Your property, health and physiological, biometric and identity information should be kept properly.” Moreover, the ‘Terms and Conditions’ displayed by the companies should be made more clear and readable.
- Even if the browsing data and other personal data get stored, there should be a time period after which the data gets deleted.
- Users should have the right to delete the data from any website at any time. Companies should take user consent before using their data.
- When personal information is seriously infringed, you should also take up legal weapons to defend your rights.
To really solve this problem more efficiently, the action of some governments and some international organizations is indispensable.

Although the European Union published General Data Protection Regulation (GDPR) in 2018 to guard data privacy, this is the only law that regulates digital privacy issues most efficiently in the entire world.
Other countries should take it as a standard and take measures as soon as possible.
From a technical point of view, developing privacy computing may be another way to ease the problem. But there is still a long way to go.

Conclusion
Privacy protection has never been more complicated or challenging than it is now, thanks to the Age Of big data. While the Internet and artificial intelligence provide convenience, each click and browse you do may result in the exposure of your personal information. If the disclosed information is exploited in other criminal ways, the ramifications will be irreparable. We can’t stop technology from progressing and ushering in the AI future, but we can start with ourselves and do tiny things within our power to protect our data privacy.


