To explain the black box problem succinctly consider the analogy of computer science researcher Elizabeth Holm for the science fiction classic The Hitch Hiker’s guide to the Galaxy”: in this book a super computer is assigned with the task to calculate an answer to life’s biggest questions about life, the universe and everything. After millions of years of calculation the supercomputer presents the long-awaited answer: 42.
What is the black box problem and why should we care?
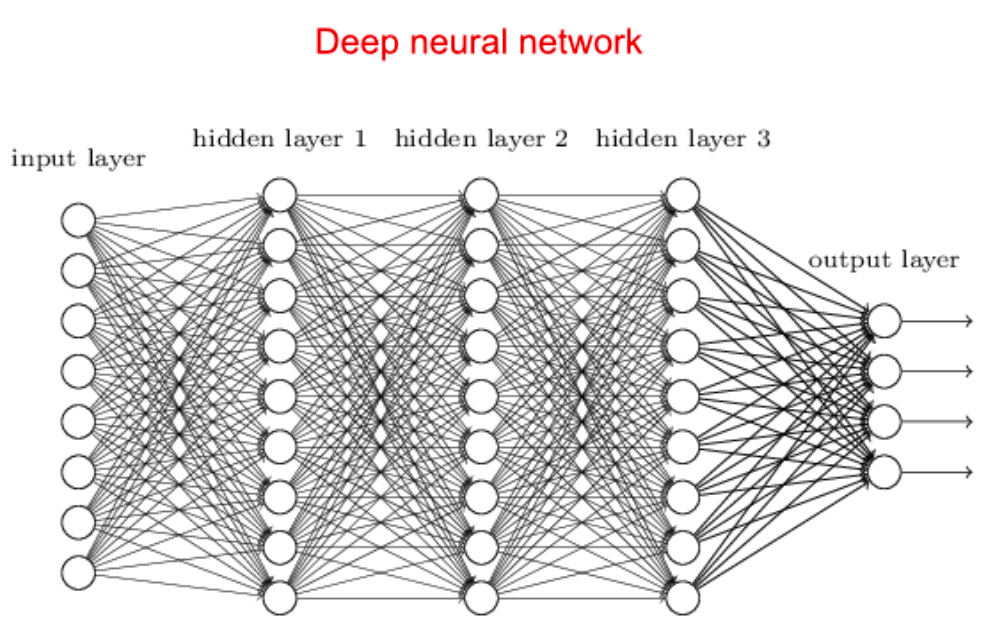
Without knowing the workings of the computer, or the precise question the computer was trying to answer, this answer is uninterpretable and useless to us. With the dawn of neural networks and deep learning, algorithms make use of countless hidden layers that process input data in order to give us some sort of output, for instance labelling pictures as containing birds or not. However, deep neural networks are trained on large amounts of data to adjust their weights and interpreting these networks has become impossible. Some algorithms search for patterns in higher-dimensional spaces which humans cannot visualise. The more complex these deep neural networks are structured, the less we are able to interpret their decision-making processes.
Why is it important whether we are able to interpret the workings of an AI algorithm, so long as it gives us the right output? Algorithms might lead to unexpected or problematic answers. One way this can happen is if algorithms acquire biases through the data that they are trained with. Consider, for example, facial recognition technology recognise white faces better than black faces, or AI’s that tag pictures of African Americans as ‘gorillas’. These biases of AI algorithms will also impact future use of AI criminal decision models responsible for assessing the risk of convicted criminals to reoffend. While these algorithms might be able to greatly reduce the costs associated with incarceration and crime, hidden biases that we cannot detect on face value (due to the hidden structure of the decision making processes) might exacerbate systemic racism and discrimination. Without understanding the workings of the AI it is hard to identify solutions to the networks that produce these results.
Another example comes from the field of self-driving vehicles, where choices of the AI can have potentially life-threatening consequences. Self-driving cars largely operate through the classification of objects on the road through computer vision. However, these choices are made in split seconds, and mistakes can endanger the life of other road users. This was the case in Arizona, when recently a self-driving uber ran over a woman, because it classified her as a plastic bag or some other object irrelevant to the breaking mechanism. This has become known as the first death related to an autonomous vehicle so far. How can we assure that such a casualty does not occur again if we do not understand the classification algorithm that caused it?

Examples of undesirable results produced by neural networks are also found in healthcare: in the 1990’s neural networks were used to give an assessment of which pneumonia patients to treat on site, and which as out-patients, because these models produced better results than conventional methods. Before the application of this algorithm, however, many asthma patients with pneumonia were admitted directly to the ICU (due to their increased risk of dying), leading to a skewness in the training data. This resulted in the neural networks predicting a lower risk of dying for pneumonia patients with asthma, only based on the fact that these patients tend to be moved into the ICU directly and not only into the hospital. As a result, these networks were taken out of order as the clinical implications of such misclassification are severe. The prevention of such mishappenings requires a thorough understanding of the applied algorithm before its deployment.
One last concern relates to the legal consequences of deploying AI in different fields. Due to the difficulty in mapping out decision-making processes of deep neural networks, it will become increasingly difficult to hold humans accountable for the deployment of such networks. This is because it will necessarily become harder to assess the intent or conduct of the person that uses a deep neural network, as we become less capable to predict their output or understand their processing. Lastly, it is noteworthy that the impact of this black box problem will increase with the delegation of more and more tasks to AI. With the delegation of more tasks to AI there will be an increased demand for comparability of different AI algorithms, making it more and more important that we are able to trust these method. However, in order to trust a tool we need to understand it, which lead to a large amount of researchers exploring alternatives to black box models.
Explainable AI
Motivated by the preceding concerns and observations, Explainable Artificial Intelligence (XAI) has been gaining increasing attention lately. Technically, there is no standard definition for XAI, but according to DARPA (Defense Advanced Research Projects Agency), which is responsible of one of the biggest XAI programs to date. XAI aims to “produce more explainable models, while maintaining a high level of learning performance, and enable human users to understand, appropriately, trust, and effectively manage the emerging generation of artificially intelligent partners”. The completion of this task has proved to be a very challenging technical issue due to problems such as ”the multiplicity of good models”: given the complicated structure of ML models, for the same input of variables and prediction targets, complex machine learning algorithms can yield equally accurate results by taking very similar but different internal pathways in the network. This is an intrinsic instability that makes it difficult to automatically generate explanations. This was studied profoundly by Hall and Gil in their introduction book to Machine Learning Interpretability. Whereas this exposes a common issue for every interpretability attempt into ML models, it does not mean that the level of opacity of these models is the same for all of them. In general, there is a trade-off between accuracy and interpretability: the most accurate ML models usually are not very explainable (for instance Deep Neural Networks), whereas the most interpretable models usually are less accurate (such as logistic regression). Given this, the most straightforward way to get to interpretable AI would be to design an algorithm that is intrinsically interpretable, but this would come at a cost of accuracy…
Hence an alternative approach would be to create highly complex black-box models with high accuracy and develop a series of techniques, some kind of reverse engineering techniques, to perform on them. This way, we would be able to provide the needed explanations of the models without altering the inner works of it. Most recent works done in the XAI field belong to this class usually referred to as post-hoc, which includes explanations by example approaches, visualizations techniques and natural language explanations.
To better understand these methods, let’s offer an example of one visualization method called Partial Dependence Plot (PDP). In this example, we have a model that, given a series of inputs (risk factors), determines the probability of a subject having cervical cancer. With Partial Dependence Plot, we can visualize the average partial relationship between one or more input variables and the predictions of the black-box model. This is, we will be able to understand the relationship between certain risk factors and the probability of having cancer. For instance, the following image shows the relationship between age and cancer, and years on hormonal contraceptives.
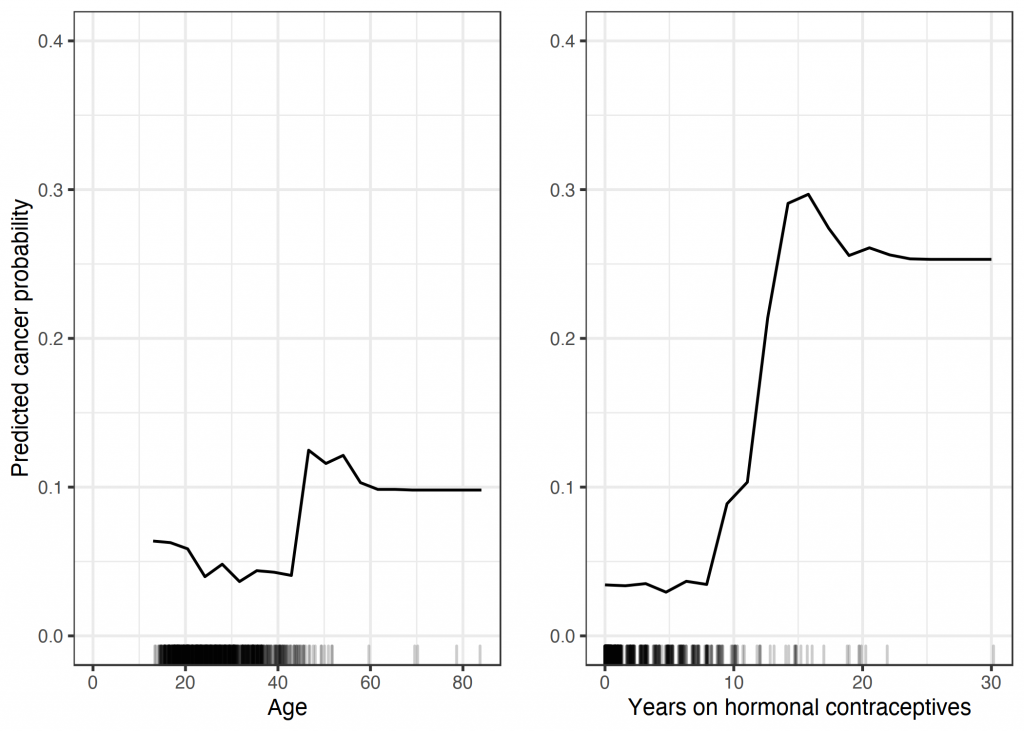
This method helps us not only to “open the black-box”, but also to find out which inputs may be biased, so that we can change the model to adapt to this situation. It can also show the relationship between to inputs and the prediction. For instance in the following figure, we can visualize it for “number of pregnancies” and “age”.
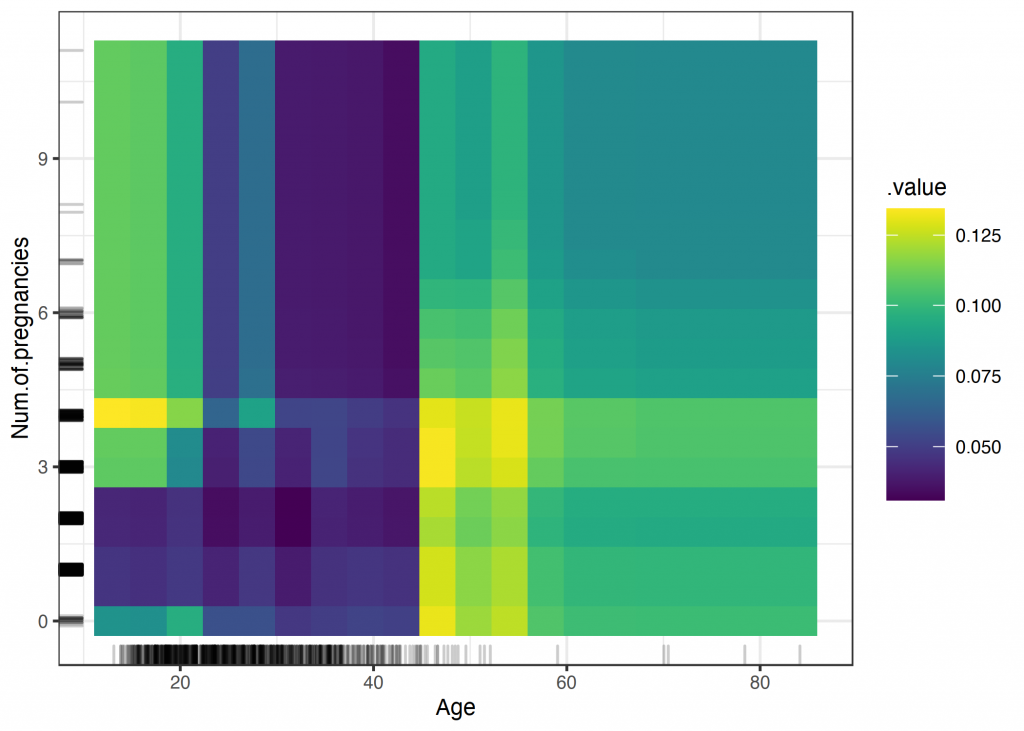
For more than two inputs, the results can not be visualized, but mathematical analysis on the predictions can also be done to draw conclusions.
Another really useful method, specially for image processing applications, is the Feature Visualization method. This approach is able to show explicitly the learned features of a Neural Network. Particularly, it is used on Convolutional Neural Networks, which are Neural Networks that are naturally made for processing images. Technically, Feature Visualization for a unit of a neural network is done by finding the input that maximizes the activation of that unit. As neural networks usually have millions of neurons, doing a Feature Visualization on every neuron would take too long. Hence, we can go one step further and visualize an entire convolutional layer.
Convolutional Neural Networks learn abstract features and concepts from raw image pixels. Thanks to Feature Visualization, we understood that the Convolutional Neural Networks learn increasingly complex features over its layers as illustrated in the following feature.

In this case, we can see the features learned by the Convolutional Neural Network “Inception V1”. The features range from simple features in the lower convolutional layers (left) to more abstract features in the higher convolutional layers (right). The first layers learn features such as edges and simple textures, whereas the last convolutional layers learn features such as objects or parts of objects.
These range of techniques allow us to better understand highly complex models, while maintaining their high accuracy.
Accepting the black box
While we outlined many of the risks associated with black box models, there is an emerging scene of advocates who present a variety of arguments advocating their use under certain circumstances. Firstly, black box models can be more accurate than other models in some applications, e.g., image processing. For that reason, the decision on whether or not to deploy a black box algorithm can be rephrased as a question of whether the benefits outweigh the risks. This might be the case when the cost of a wrong answer is low compared to the value of a correct answer, as for instance in advertising. But this might also be the case when the black-box model simply performs better than a white-box model, e.g., when a cancer-detection algorithm outperforms the evaluation of a radiologist. While these decisions have a high cost associated with false positives or false negatives, the black box model might still outperform any alternative and thus save more lives in this particular application.
There are also some approaches that try to combine white and black-box models. These approaches aim to use explainable algorithms for subtasks that are crucial for our understanding, and delegate the other subtasks of the algorithm to black box models. However, any of these arguments assume our ability to estimate the costs and benefits of the deployment of such models. Both of these assumptions can be highly contested, especially with the decreasing transparency of the algorithm’s workings. Furthermore, we cannot use black box models to further our understanding of something or establish causation or systemisation, which is desirable in many areas in which AI is utilised. Additionally, as our description of biased algorithms has shown, any developer aiming to build such a network needs to be familiarised with the input data and preconceive a desired way of presenting the results before any application. Lastly, developers should keep monitoring their algorithms if these continue to adapt to the problem at hand.
How should we move forward?
The risks of black-box models are manyfold, as for instance in health care, the legal system and in self-driving cars. The use of such models should be weighed in terms of their risks, costs and benefits, which might prove difficult due to the intransparent nature of their processes and, in some cases, their ability to adapt and change. Thanks to Explainable Artificial Intelligence methods, we are starting to understand black-box models, which opens the possibility of not relying on white-box models, hence maintaining the high accuracy achieved by more complex architectures. Furthermore, black-box algorithms can be more accurate than white-box models, and an integration of black-box components into white-box algorithms is possible to decrease the risk associated with their use. In fields where the risk outweighs the potential benefits, explainable AI should be used. We conclude, however, that where the risks are easy to assess and outweighed by the value of deploying a black box model, such a model can and should be used.