A century ago the world’s most valuable resource became oil. This started a powerful thriving industry that changed the world. Its power was so concentrated that it eventually caused regulators to step in and create new antitrust regulations to tame the industry and the companies behind it. Today, the most valuable resource is no longer oil, but data. The switch in valuable resources has made way for a new industry with powerful companies that deal in the resource. Currently 4 out of the top 5 most valuable companies deal in data; Amazon, Alphabet, Microsoft and Apple. The other company in the top 5 is Saudi’s oil-driven Aramco.
The way oil is won is a very tangible process; a very long rod is drilled into the ground to where an oil spring is and then oil is pumped up to the surface. The process for gathering or mining data is much less tangible. However, this time it affects you personally a great deal more as data is collected from individuals through platforms such as Facebook and those individuals are even addicted to the process. It is constantly happening to all of us, most often with us not being aware of it at all. Who you talk to, what you talk about, what you like, your interests, transactions, face and much more is gathered by these kinds of data collecting platforms. Your personal data is then used to create models that yield value for the creators, but probably not for you. So whilst others are making a lot of money off you, you are not seeing a penny.
It is essential that we start to see the value of our data so that we become aware of how often our data privacy is violated. Your privacy is at a constant risk of violation because companies gather our data in shady ways and circumvent any lacklustre privacy regulation that has been implemented, by use of artificial intelligence. But even with AI being a risk towards your privacy as it is now, we actually think that AI itself can be the tool to improve it whilst not degrading the utility of data.

The value of your data
It is unlikely that you are aware of the value that your data yields. Data platforms provide little to no information to the average consumer about this. Which is on purpose as the data platforms know that you would be much less likely to freely provide data if it was transparently valued. Using statistics from 2016 and rudimentary maths it is estimated that you could earn $240 by monetizing all of your own data, a figure that is likely to be much more now in 2022.
Whilst they are actively keeping you out of the loop, companies themselves are very aware of the value that your data provides. They are very happy to receive the data of others, but are unwilling to share theirs. Facebook earned $114 billion through its advertising driven by data in 2021, which accounted for 99% its total income. Alphabet’s revenue through advertising accounted for 93%, or $70 billion, of its total income for a single quarter in 2021. Gathering as much data as possible of users has turned into absolute crucial processes for these companies.
These data-driven platforms are still enjoying growing user bases. The average consumer seems to be completely unaware about how they themselves have turned into the products. Would you be willing to pay these platforms $240 a year to continue using them? Because that’s what you’re effectively doing by using them. You might not be paying this in monetary value, but in the form of your personal data. And the worst thing is that you are likely addicted to this process. And even if you aren’t, it might just be outright impossible to use these platforms and avoid giving your data.
Lawmakers are starting to grasp the extensive data mining and power of these companies. In 2018 the European Union introduced the General Data Protection Regulation. Also in 2018 the state of California introduced the California Consumer Privacy Act, which has turned into the de facto law for the United States. Both of these regulations aim to increase privacy and improve personal data rights. But as the value of data is still unclear to the consumer they seem happy to keep giving it away. Additionally, the companies most affected by the regulations seem happy to ignore it and take on its fines.
What companies do to get the value from your data
Besides not being aware of the value of our personal data, we are also quite unaware of the methods we have complied with that are used to gather our data. And most probably you will not agree on these methods, because they are quite shocking. It is not only your zip code and telephone number that are gathered by companies and sold to the next. Our behaviour is analysed so it can be influenced. And for this there is only a need for your tweets, your clickstream behaviour, your walking pace that is recorded by your phone or the way you use your keyboard. From cinemas that track your emotional state throughout a movie with facial recognition, to digital assistants that are always listening. All this makes up your personal big data, and that data will be analysed with artificial intelligence.
And would you be happy that your local supermarket is able to guess when your baby is due? The huge amount of data that is collected is often analysed by what is called data mining. Data mining is the process that organisations use to find patterns that can be used for prediction to increase profit. Though data mining is often done on completely anonymized data sets, there are still concerns for privacy breaches. Target used transactional behaviour to predict if women were pregnant. They found out that women started buying more products in specific periods of their pregnancy, like a change from soap to unscented soap or a sudden increase in the amount of cotton balls. By combining the shopping behaviour of around 25 products, Target was able to predict if women were pregnant and even could predict in what period they would give birth. This resulted in sending discount coupons to their houses for baby clothes and such. A father got angry towards Target as he found it ridiculous that this was sent to his daughter who was still in high school. It turned out that Target knew the daughter was pregnant before the father was aware of it. This shows that for companies to use your data in the most profitable way results in what most people see as a violation of their privacy.
You can’t be anonymous
Would it then not be enough to have companies try to anonymize the sensitive personal data to protect the privacy of individuals. Data masking is an umbrella term for methods to de-identify data, methods like anonymization, obfusciation, and pseudonymization. Pseudonymization is a fairly cheap method of data masking and consists of replacing personal identifying information with artificial identifiers. The data becomes less identifiable while keeping the quality of the data for processing. The problem with pseudonymization is that it is often very easy to re-identify the data. Using pseudonyms can be reversed when one figures out the method the pseudonyms are created with. This becomes more easy the longer a pseudonym is used. A data scientist found out in which way the taxi medallions, which are unique taxi permits, were pseudonymized within a dataset of all taxi rides of New York. Combining this information with the medallions in pictures taken of celebrities entering cabs, made the scientist able to determine location of pickup and dropoff, the cab fare and even how much was tipped by these celebrities. This shows again how easy it is to gather personal information that you want to keep private. And it is not only because of weak data masking.
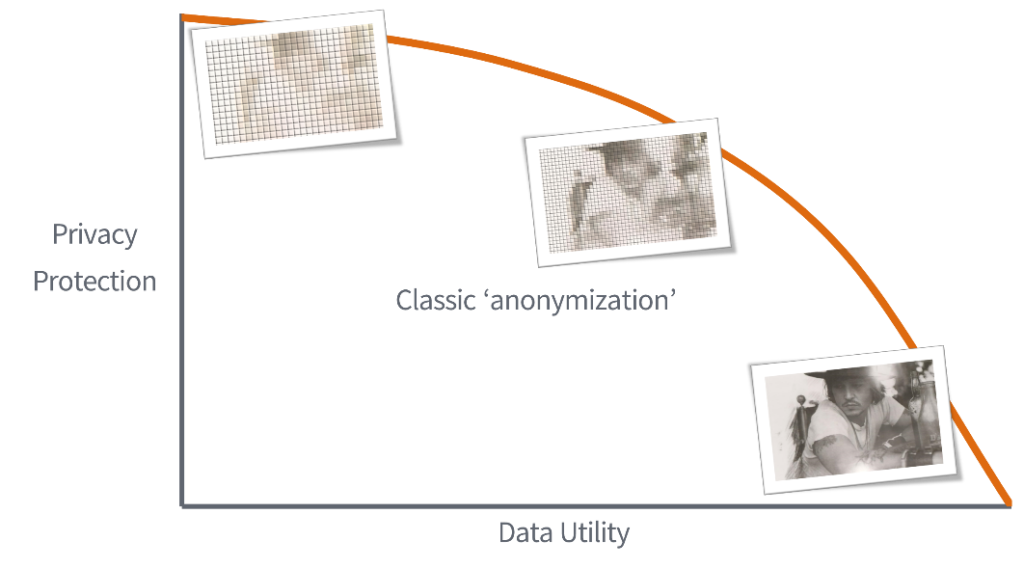
An even more efficient way to collect sensitive information of individuals, is the linking or combining of anonymized datasets which contain the same individual. Dr. Sweeny had shown how one could link the voting registration data, bought for a few dollars, from a certain district could be combined with the hospital dataset to find sensitive medical information from unique individuals. Governor Weld of Massachusetts who assured the public that the medical data that was being shared was properly anonymized, had his own medical information found by Dr. Sweeny. Her method consisted of having overlap in indirect identifying information in both datasets, like zip codes and gender. This was done in the 90’s, nowadays we have way more efficient methods reidentifying by combining datasets.
And that is shown in the new approaches of AI used to identify individuals in anonymized datasets. With stronger algorithms it is now possible to relate behaviour to individuals. So even if all your data is properly anonymized, companies do not even need that personal identifying data at all. A paper showed how behavioural clickstream data that is anonymized could easily be re-identified with neural networks. The researchers behind this paper wanted to show that highly dimensional, highly correlated data that often arises after observing individuals for a longer period of time makes it difficult to properly anonymize with data masking methods. They showed that datasets do not even require an overlap in identifiers, as was the case in Dr Sweeny’s experiment. By analysing behaviour one can utilise the behavioural patterns in two different datasets without overlap of data points and match the same behaviour to one individual. They even showed that multiple methods of data masking, like adding random noise, is not efficient against these so-called pattern attacks.
Lawmakers are eager to make a change
One could argue that regulation and law enforcement can be the solution for the protection of individuals’ privacy. Four years ago the The GDPR was implemented in Europe as a directive for the protection of data privacy of individuals. This law forces companies to determine and properly anonymize all personal identifiable information data. But there are multiple issues with these regulations to properly protect everyone’s data privacy.
The GDPR is a strict and encompassing law. All personal identifying information needs to be determined in datasets and anonymized. Also companies need to argue why they are gathering specific data and must always have consent of the individuals. The implementation of the GDPR with its strong penalties for companies not following the rules, showed success in the last few years. Data breaches resulted in huge fines for companies. The GDPR being so all-encompassing is one of its strengths but also one of its weaknesses. The scope to properly check if companies are using ‘proper methods of anonymization’ is an enormous task for which they lack the capacity, while at the same time the amount of money companies need to spend to comply with the GDPR is so high that smaller companies really are being hit harder than bigger companies. Besides, there are so many different kinds of data, there is no directive on what it means to properly anonymize the data.
We already showed you how easy it often is to reverse anonymization of data and also that it is not even necessary to use personal identifying information but behaviour to identify individuals, the artificial intelligence tools that companies use to infer data from behaviour is not under any regulation of the GDPR at all, those are even protected as trade secrets. So unfortunately regulation is not the complete solution we need to protect our data privacy.
Artificial intelligence can make the difference
We hope that people will start becoming more aware of the amount of data they give away and the value this provides. Why would you give away your personal information for a newsletter? And why does Facebook need to know where you are to stay in touch with your family and friends? It’s time to start being much more aware of what all the companies and organisations you are interacting with know about you. How much of that did you cause yourself because you are giving away your information without questioning it. But also the amount of information that can be triangulated. The average consumer needs to start consciously contributing their data. Not only will this give them more leverage, it’s also beneficial to an equal industry and artificial intelligence itself. Whilst this would be the best start, it in itself will not be enough, as long as privacy and data value are in competition with each other, new methods to collect more data will result in risks to your privacy.
The next first thing that can really make a change will be the use of synthesised datasets. Synthesised datasets are datasets created by artificial intelligence that are derived from existing datasets. Deep Fakes are also created in a similar way and whole datasets of people’s faces can be created, though no face is of an actual person. These dataset bring forth the same statistical properties as the original datasets, but the data has been altered in ways that it does not depend on or contains the original personal identifying information. And because of this artificial intelligence methods to re-identify have no succes. And that is not the only advantage of synthesised datasets. Sometimes it is very difficult to gather some data because of the low frequency of these events, with synthesised data these datasets can be expanded, which in term helps the training of algorithms. Synthesised data can also be used to enforce datasets with strong biases, e.g. underrepresentation of a certain phenotype in medical datasets can be supplemented with synthesised data to counter this underrepresentation. While the reduction of bias in data is in itself a goal, this also leads to better results for the training and performance of algorithms.
The second thing we call for is to change the way we find information in data. Data analysis like data mining can be more privacy preserving. Data analysis is not much more than finding statistics in big datasets in the end. So if you ask for just the average of the age of the dataset this tells nothing about the individual people making up the dataset. This only changes when one keeps on finding more and more of these statistics about the same group, the combination of the statistics can be used to reconstruct the dataset to a certain degree. One can find out in the end if some individual was part of the dataset. This is the law of information recovery. And it is at the heart of wanting to use data as much as possible which in the end destroys the individuals their privacy.
What is needed is what is called differential privacy. We need a way to do analysis that is meaningful but in the end does not depend on the individuals in the dataset, so the analysis result should not change when one individual is swapped for another. A way to do this is to add noise to datasets before it goes into analysis, like flipping answers from yes to no or vice versa. This makes the data more private but you could easily see that this also diminishes the data value. This is because machine learning builds on the idea that the data is stable, but every time you ask for the dataset, the stochastic noise that is added results in different datasets. And in this way you can not create stable algorithms. The key aspect of differential privacy to work for AI is that you tell how much noise is created. If you want to know how many people said yes to a certain question, and you add noise by having an answer flipped by a certain chance. By knowing how big the chance is of flipping, you can still calculate an estimate of the original fraction of yes answers. But you will never know exactly who said yes and who said no. In this way we can do privacy preserving data mining.
Violating people’s data privacy becomes way less of a problem with the use of synthesised datasets and differential privacy because the data is still of very high quality while retaining the privacy. It shows that privacy and data utility are not necessarily in competition with each other. Therefore with the combination of regulation, conscious data contribution of the individuals and AI, we can regain our privacy whilst our data keeps its usefulness.



